
探すこと。ときどきふと、じぶんは人生で何にいちばん時間をつかってきたか考える。答えはわかっている。いつもいちばん時間をつかってきたのは、探すことだった。長田 弘『最後の詩集』
探索と検索、それぞれの意味
私たちは日々の生活の中で、さまざまなものを探し求めています。着るものや食べるものに始まり、勉強や仕事に必要なもの、趣味や娯楽として手に入れたり体験したいもの、問題や悩みごとを解決する方法や手がかりなど、ありとあらゆる「探しもの」をしています。
「探しもの」をするのは人間だけではありません。食物や住処、求愛の対象や仲間を探すといった行動は、動物たちも行なっています。でも、インターネットとWebの技術が誕生したことで、人間の「探しもの」の可能性は、それ以前よりも大きく広がりました。昔から、他の動物と同じようにオフラインで行なってきた「探索(seeking)」という普遍的な行動に加えて、人間はオンラインで情報を探す「検索(searching)」をするようになったからです。そして、必要な情報を探し出せるかどうかは、私たちの生活に深く関わってくるようになりました。
Webがまだ生まれていなかった時代に、カリフォルニア大学で情報検索の研究をしていた図書館情報学者マーシャ・ベイツは、「探しもの」を行なう場所がオフラインからオンラインへと移行する中で変化しつつあったユーザーの行動を探ろうとしました。そして、「オンライン検索インターフェース向けのブラウジング/ベリーピッキング技法の設計」と題した1989年の論文で、彼女が提示したベリーピッキングという新たなモデルは、後のWebでの情報検索に大きな影響を及ぼすことになりました。
情報検索の古典的モデルの限界
ベイツが論文を発表した当時は、学術機関や図書館で各種のデータベースのオンライン化が着々と進んでいる時代でした。調べものをするためにそれらの施設を訪れて、手作業で必要な本や論文を見つけ、ページをめくって探していた情報が、コンピュータを使ってオンラインで探せるものになりつつあったのです。
ただし一方では、オンラインでの検索が複雑化するという問題も生じていました。利用できる情報源の種類が増え続けると同時に、より込み入った条件で検索するには、ますます高度なテクニックが必要になってきたからです。ベイツが先の論文を書いたのは、現状に見合わなくなった古典的な情報検索モデルに代わる新たなモデルを示し、もっと使いやすい検索システムの設計に活かすためでした。
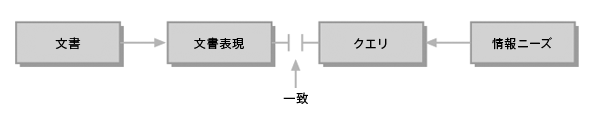 図1 古典的な情報検索モデル
図1 古典的な情報検索モデル
情報科学の分野で長らく用いられてきたという、この古典的モデルが示すタイプの情報検索は、「IR(Information Retrieval)」と呼ばれていました。『図書館情報学用語辞典』では、この用語を以下のように定義しています。
あらかじめ組織化して大量に蓄積されている情報の集合から、ある特定の情報要求を満たす情報の集合を抽出すること。主にコンピュータの検索システムを用いる場合に使われる言葉である。検索対象によって情報検索を分類すると、事実検索と文献検索に分けられる。前者は求める情報そのもの(事実やデータ)を探し出すことであるのに対して、後者は求める情報が掲載されている文献の書誌データなどを探し出すことである。日本図書館情報学会 用語辞典編集委員会 編『図書館情報学用語辞典 第4版』
図1のモデルと上記の定義を見ると、当時の情報検索は、かなり限定的だったことがわかります。検索できる文書は、それぞれの学術機関や図書館で管理している資料や蔵書に限られた上、全文検索がスムーズにできるほど技術が発達していなかったために、検索の対象となるのは文書そのものではなく、書誌や目録、抄録、索引といった文書表現(document representation)※1であるのが普通でした。したがって、ライブラリアン※2が作成する文書表現と、ユーザーが入力したクエリ(検索語句)がぴったり一致しなければ、望ましい検索結果は得られません。いわば、ライブラリアンとユーザーがお互いの胸の内を探り合う必要があったので、どちらにとっても検索は厄介なものとなっていました。
オンラインでの情報検索が複雑化し、古典的モデルに見合わなくなってきたため、ベイツはユーザーの行動の流れ(シーケンス)を重視しました。そして、よりリアルにその実態を反映した、「ベリーピッキング(berrypicking)」という新たなモデルを生み出したのです。
ベリーピッキングモデルが伝えるもの
昔からオフライン環境では、大まかなトピックの一つの特徴、あるいはそれに関係する一つの資料を出発点として、次第にさまざまな情報源を渡り歩いていくという探索が行われていました。図書館で見つけた一冊の本をきっかけとして、関連する他の本も調べていくうちに、新たな発想や情報ニーズの変化が生じるということもあるのではないでしょうか。オンライン検索でも、一度手に入れた結果に基づいてクエリを修正し、再検索をすることは多いですし、クエリの性質自体も移り変わっていくことがあります。ベイツはこのような検索を、「発展的検索(evolving search)」と呼びました。
古典的モデルの検索では、答えが一度にまとまって返ってくることを想定していましたが、実際には、いくつもの手法を用いてその都度得られる情報を選り集めたものが答えになると、ベイツは考えました。こうして少しずつ成果を集めていく発展的検索を示したのが、以下のベリーピッキングモデルの図です。森の中では、ブルーベリーやラズベリーが実っている場所が散らばっているので、あちこちで少しずつ摘み取っていくことになります。オンライン検索も、そのような「ベリー摘み」によく似ているのです。
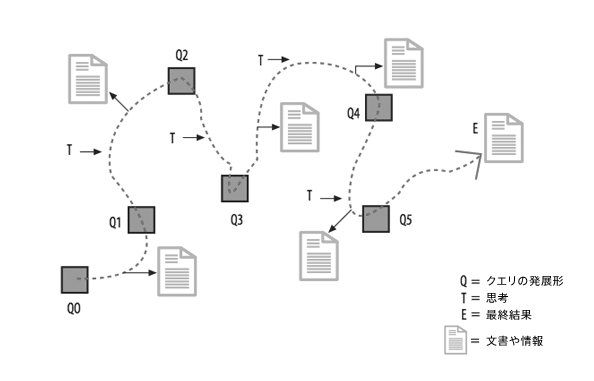 図2 ベリーピッキング:発展的検索
図2 ベリーピッキング:発展的検索
ベリーピッキングは、古典的モデルが示す一致の単なる繰り返しではないか、という疑問を感じるかもしれませんが、情報との出会いが多種多様な形で生じるのがベリーピッキングならではの特徴です。つまり、検索の手法があれこれ変わっていくだけでなく、検索の対象となる情報源が、形態的にも内容的にも変化していくのです。古典的モデルのように、1回のクエリで最終結果をひとまとめに受け取ることがあるとしても、それはベリーピッキングの体験全体から見れば、一つの場面にすぎません。
ベイツのベリーピッキングモデルは、Webでの情報設計の考え方やノウハウを初めて体系的に紹介した書籍『Web情報アーキテクチャ』や、その共著者の一人であるピーター・モービルの『アンビエント・ファインダビリティ』で紹介され、Webに関わる人々の間でも知られるようになりました。ただしベイツの論文には、そのどちらの本にも載っていない、もう一つの図があります。それは、ベリーピッキングをする探索者の「関心の世界(universe of interest)」の外に、もっと大きな「知識の世界(universe of knowledge)」が広がっていることを示していました。
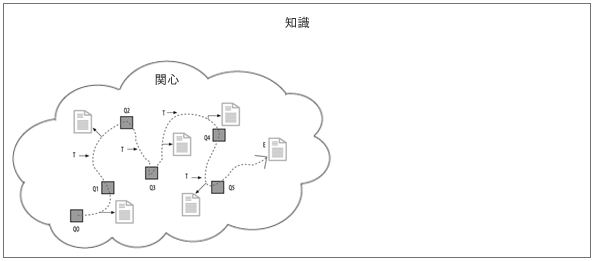 図3 ベリーピッキング検索のコンテクスト
図3 ベリーピッキング検索のコンテクスト
広大な「知識の世界」は、「ノウアスフィア(noosphere)」※3と呼ばれる、人間の思考の圏域を想い起こさせます。そして、「関心の世界」を囲む雲のような境界線は、探索者による認識の限界を示していると言えます。その外側にあるはずの「知識の世界」について、自分はまだその存在さえ知らないかもしれない。でも普段の私たちは、それぞれの「関心の世界」の内側で、ほぼ安泰に暮らしています。それは、あらゆる動物が、自らの知覚情報から成り立つ「環世界」※4を、まるで世界そのものであるようにして生きていることに似ています。でも、何かのきっかけや思いつきで「関心の世界」が広がるのは、多くの人が経験していることでしょう。
図2をズームアウトして、一回り大きな観点からベリーピッキングの全体像を描いたこの図について、ベイツはほとんど説明を加えていません。人間が各自の「関心の世界」に閉じ込められがちな傾向に気づかせようとしたのか、あるいは、「関心の世界」を広げる余地はいくらでもあるという見方を伝えようとしたのか。彼女がこの図に込めたメッセージをどう受け止めるかは、見る人次第となるはずです。
オフライン探索における6つの手法
ベイツはこのベリーピッキングモデルに基づき、従来オフラインで行なわれていた書籍や文献の探索行動を調べながら、オンラインの検索システムに望まれる機能を考えていきます。そして、他の研究者の説も採り入れながら、主要な探索の手法を以下の6つにまとめました。
- 脚注追跡(または後方連鎖)
書籍や論文の脚注や参考文献リストをたどる。社会科学や人文科学では特に多用される。 - 引用文献検索(または前方連鎖)
書籍や論文の引用索引(citation index)※5を見て、他のどんな文献がそれを引用元にしているかを調べる。 - ジャーナル調査
ある分野での主要なジャーナル(学会誌や雑誌などの定期刊行物)を見つけ、そのバックナンバーを調べる。 - エリアスキャン
図書館などで見つけた本や資料を調べるとき、それと物理的に近い場所にあるものまで調べてみる。 - 主題別検索
書誌や抄録、索引などの二次情報で提供されている主題別の分類を利用して、書籍や論文を探す。図書館ではもっとも親しまれている方法。 - 著者別検索
ある著者について、同じ話題を扱う他の著作物があるかを調べる。
オフライン探索の手法は他にもありましたが、当時のオンライン検索システムは大抵、「5. 主題別検索」しか十分にサポートしていませんでした。それが図書館情報学において、他の手法より優れているとみなされてきたことも、その一因だったようです。
でもその頃には、「5. 主題別検索」よりも「1. 脚注追跡」のほうが頻繁に行なわれている事実を明らかにした調査結果も出てきていました。実は大いに役立っている手法が、正しく評価されていなかったことになります。また、「2. 引用文献検索」で必要となる引用索引は、長らく正当に評価されていませんでした。そんなものは、自分の本や論文がどれだけ引用されているかを学者たちが知って自己満足に浸るためにしか役立たない、という批判さえあったといいます。
自らが属する図書館情報学の分野でそのような経緯があったことを知り、深く反省したベイツは、それぞれの手法の有効性をきちんと認めるべきだと考えました。そして、オフラインでの探索では、多くの手法が利用できるほどユーザーの満足度が高いことが明らかになっていたため、オンラインの検索システムでも、先の6つの手法すべてを機能として提供することを主張したのです。もちろん彼女は、ただ多くの機能を寄せ集めることを提案したのではなく、ユーザーのベリーピッキングを促すように、操作手順をシンプルに覚えやすくして、ある機能から他の機能へとスムーズに切り替えられることを重視していました。
ブラウジングの価値を引き出す設計方針
ベイツは、それらの手法をオンラインで実現するための具体的なアイデアを挙げていきます。まず最初に見直したのは、オフラインで昔から行なわれてきたブラウジングという行動の重要性でした。
実はその当時、「通常の」探索と言われるのは、探したいものがわかっている有向的(directed)な検索のことでした。かたやブラウジングは、明確な目的もなく気ままに探しものをする、無向的(undirected)な行動とみなされていました。ブラウジングという言葉の元の意味は、家畜を放牧して飼料としての若葉や新芽を自由に食べさせることで、まさにそんなイメージを持たれていたのです※6。そのため、当時のオンライン検索システムでも、有向的検索が主要な機能とされており、あちこち見て回るというブラウジングがしやすい設計は行なわれていませんでした。
しかし、発展的なベリーピッキングのプロセスを考えるようになると、従来とは見方が違ってきます。有向的検索とブラウジングが、常にはっきり区別できるとは限らないからです。それを示唆するかのように、シェフィールド大学のデヴィッド・エリスは、標準的な探索行動で重要な役割を担うようなブラウジングを、半有向的(semi-directed)検索または半構造化(semi-structured)検索と呼びました※7。つまり、探す対象は決まっていないけれど、まったく目的がないわけでもなく、何か面白いものや役に立ちそうなものが見つかることを願っているようなブラウジングのことです。
エリスの考え方に共感していたベイツは、検索システムがもっとブラウジング機能に目を向けることを期待して、ナビゲーションやインターフェースに関わるさまざまなアイデアを示しました。それらを通じて彼女が何を目指したかを考えると、オンラインのシステムにおける2つの設計方針を見出すことができます。
効率性とセレンディピティを共に高める
ベイツが注目していた探索行動は主に学術研究を目的としていたので、まずはいかに効率よく、確実に検索を進められるようにするかが重要でした。たとえば、「1. 脚注追跡」をしていて本文をどこまで読んだか見失ってしまうと、元の場所を探すのに無駄な手間と時間がかかります。印刷物の脚注は、各ページの下部にあるか巻末にまとめられている※8ことが多いですが、画面上ではポップアップ表示のように紙の上ではできない見せ方も考えられます。どんな場合でも、本文と脚注の間をスムーズに行き来できることが不可欠だと、ベイツは考えました。彼女は他の探索手法についても、ナビゲーションの経路を短縮したり、検索結果を多角的にグループ化して見やすくするなど、効率を高めるためのアイデアをいくつか挙げています。
しかし、ベリーピッキングという探索行動では、必ずしも効率的とは言えないブラウジングが、また別の重要性を持つことになります。ブラウジングは、思わぬところで自分の興味をそそる情報に出会えるというセレンディピティを高め、新たな刺激や発想を与えてくれる可能性があるからです。
たとえば、「2. 引用文献検索」で利用する引用索引は、セレンディピティにつながりやすい、雑多な情報が集まった場所と言えます。同じ引用元を参照しているという共通点はあるものの、それぞれの情報源で扱っている話題は、かなりバラエティに富んでいるかもしれないからです。また、昔から図書館で多くの利用者が「4. エリアスキャン」をしていたのも、あちこち動き回るほど予想外の発見をしやすくなることが大きな理由だと、ベイツは考えていました。
ベリーピッキングは、探索者を単に効率よく結果に導くだけではなく、時にはセレンディピティをもたらすこともできる、複合的な探索行動です。ベイツは、一見すると相反しそうな2つの価値を併せ持つ複合性が、人間の探索行動を豊かにしてきた鍵だと考えたからこそ、効率性ばかりを追いがちな検索システムにも、オフラインで「関心の世界」を広げてきたセレンディピティを採り入れようとしたはずです。そうすれば、オンラインでの探索も、あらかじめ決まった目的を果たすだけの行動ではなく、時にはその目的そのものを一新させたり、未知の世界に目を開かせたりする、より豊かな体験となるからです。
情報のアバウトネスやセマンティクスを伝える
アバウトネス(aboutness)とは図書館情報学の用語で、ある情報が扱っている主題、つまりそこで表現されている重要な概念やテーマは何かを示すもののことです。これは必ずしも客観的ではなく、個人の立場や主観によって決まるものなので、著者と索引作成者と利用者の3種類のアバウトネスがあると定義されています。したがって、古典的な情報検索モデルにならうと、文書表現が索引作成者アバウトネスを表わし、クエリが利用者アバウトネスを表わしていると言えます。
たとえば「3. ジャーナル調査」についてベイツは、広く一般的な主題を扱うジャーナルよりも、主題が絞り込まれているものの方が、細かい情報ニーズを満たしやすいと述べました。専門性の高いジャーナルほど文書表現を具体的にできるので、専門用語などを含むクエリに一致しやすくなるからです。ベイツは、検索対象となる情報が急激に増えつつあった当時、なるべく手間と時間をかけずに適切な文書表現を用意できることが肝心だと考えていました。
Webサイトの検索結果では、文書にとっての文書表現と同様に、タイトルや概要などのメタデータがサイトのアバウトネスを示しています。それが詳細であるほど自分のニーズに見合うかどうかを判断しやすくなるという点は、文書表現と共通していますが、メタデータにはさらに重要な役割があります。それは、文書の主題を伝えるアバウトネスだけではなく、その意味的構造、すなわちセマンティクス(semantics)を記述し、コンピュータが解釈できる共通の形式で意味を付与するという役割です。そのように、メタデータを利用して情報の意味をより豊かに表現しようとする考え方は、後に生まれたセマンティックWeb※9の概念に引き継がれました。
絡み合う探索/検索のモード
もう一つ興味深いのは、ベイツがオフラインでのブラウジング行動に見られる身体性に注目していたことです。本を探して図書館の中を歩き回るとき、私たちは身体全体と目の両方を、かなりランダムに動かしていることになります。画面上で全身を動かすのは無理でも、視線をあちこち動かせるようにするには、情報を時間や空間の関係に従って並べたり、書架や目録カードのようなオフライン環境のメタファーを活用することが役立つと、ベイツは考えました。
またベイツは、気になるものを次々にたどっていくベリーピッキングには、ハイパーテキストを用いるアプローチがぴったりだということも明言しています。計算機科学者のティム・バーナーズ=リーが、ハイパーテキストを駆使したWebのシステムを世界で初めて構築したのは、この論文が発表された翌年のことでした。きっと彼女は、自分が期待していた未来がついに訪れたように感じ、その新たな技術を歓迎していたはずです。
それ以来、かつてないほど大量の情報が蓄積され流通するにつれて、「関心の世界」と「知識の世界」の差は広がる一方となっています。だからこそ、ベリーピッキングという発展的な探索行動は、「関心の世界」を広げていくための技法として、ますます価値を増しているのではないでしょうか。
この論文から14年後の2003年、インターネットとWebがめざましい成長を遂げている中で発表した「情報の探索と検索の統合モデルをめざして」という論文で、ベイツは情報探索行動を社会的・文化的に理解しようとするだけでなく、先に述べた身体性というポイントにつながる生物学的な観点からもアプローチすることを試みました。私の次回の記事では、再びベイツの論文を手がかりに、人間にとっての「探しもの」についてさらに考えていきます。